Abstract
Community ecologists and macroecologists have long sought to evaluate the importance of environmental conditions in determining species distributions, community composition, and diversity across sites. Different methods have been used to estimate species–environment relationships, but their differences to jointly fit and disentangle spatial autocorrelation and structure remain poorly studied.
We compared how methods in four broad families of statistical models estimated the contribution of the environment and space to variation in species occurrence and abundance. These methods included redundancy analysis (RDA), generalized linear models (GLMs), generalized additive models (GAMs), and three types of tree-based machine learning (ML) methods: boosted regression trees (BRT), random forests, and regression trees. The spatial component of the model consisted of Moran’s eigenvector maps (MEMs; in RDA, GLM, and ML), smooth spatial splines (in GAM), or tree-based nonlinear modeling of spatial coordinates (in ML).
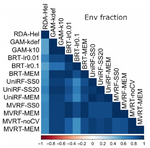
We simulated typical site-by-species data to assess the methods’ performance in (1) fitting environmental and spatial models, and (2) partitioning the variation explained by environmental and spatial predictors. We observed marked differences in performance among methods generally caused by their different performances in fitting spatial structures. Generalized linear model and BRT with MEMs were generally the most reliable methods for partitioning the variation explained by environmental and spatial effects across a wide range of simulated scenarios. The remaining methods tended to underestimate pure spatial effects, because of either underfitting of simulated spatial structures or overestimation of environmental effects compared to spatial effects when jointly estimated. Performing variation partitioning on nine different empirical datasets using these methods yielded contrasting results, especially in the estimation of the spatial fraction of variation.
Our results suggest that previously overlooked methods for performing variation partitioning, especially tree-based ML, offer flexible approaches to analyze site-by-species matrices. We provide general guidelines on the usefulness of different models under different ecological and sampling scenarios, for species distribution modeling, community ecology, and macroecology.